7.3 Least Squares
Introduction
A climate researcher has ten years of temperature data and wants to identify a warming trend. There are ten data points but only two unknowns – the slope and intercept of a line. No single straight line can pass through all ten points perfectly. So what is the “best fitting” line?
Least squares provides a mathematically rigorous and elegant answer to this question. It finds the solution that minimizes the sum of squared errors across all data points. Least squares is ubiquitous in modern engineering and data science: linear regression, signal reconstruction, robot localization, computer vision – the list goes on.
Problem Setup
Overdetermined Systems
When the number of equations $m$ exceeds the number of unknowns $n$ (that is, $m > n$), the system $A\vec{x} = \vec{b}$ typically has no exact solution. Instead, we look for the $\hat{x}$ that minimizes the residual:
\[\hat{x} = \arg\min_{\vec{x}} \|A\vec{x} - \vec{b}\|^2\]The quantity $|A\vec{x} - \vec{b}|^2$ is the sum of squared errors across all equations:
\[\|A\vec{x} - \vec{b}\|^2 = \sum_{i=1}^{m} ([\text{row } i] \cdot \vec{x} - b_i)^2\]
The Normal Equations
Derivation: A Geometric Perspective
The vector $A\hat{x}$ lives in the column space $C(A)$. When $\vec{b}$ is not in $C(A)$, minimizing $|A\vec{x} - \vec{b}|$ is the same as finding the orthogonal projection of $\vec{b}$ onto $C(A)$.
The key condition for projection: the residual $\vec{r} = \vec{b} - A\hat{x}$ must be orthogonal to $C(A)$. That is, for every column $\vec{a}_j$ of $A$:
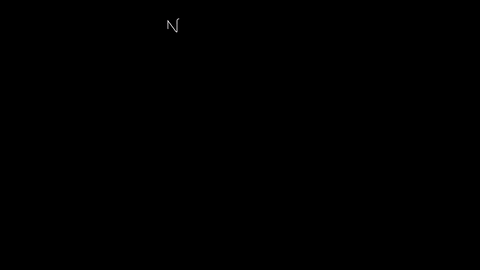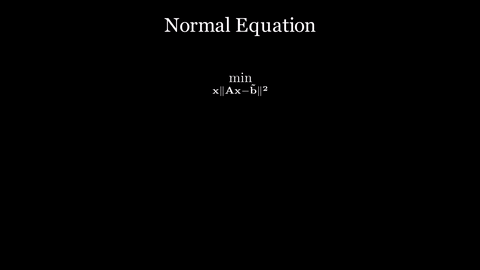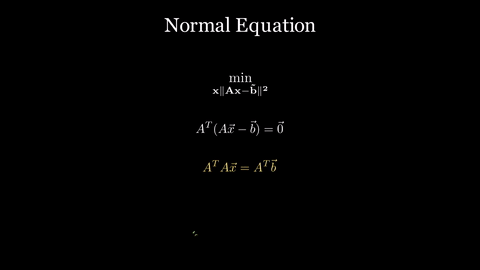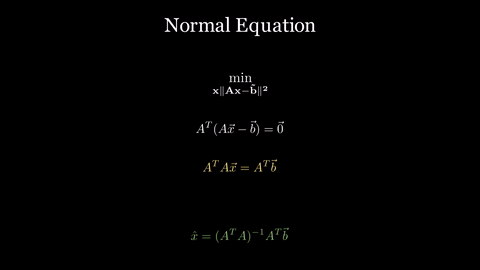
\[\vec{a}_j \cdot (\vec{b} - A\hat{x}) = 0 \quad \text{for all } j\]Writing this in matrix form:
\[A^T(\vec{b} - A\hat{x}) = \vec{0}\] \[A^T A\hat{x} = A^T\vec{b}\]These are the normal equations.
The Least Squares Solution
If $A^TA$ is invertible (which happens precisely when the columns of $A$ are linearly independent):
\[\hat{x} = (A^TA)^{-1}A^T\vec{b}\]The matrix $(A^TA)^{-1}A^T$ is a special case of the pseudoinverse, sometimes written $A^+$.
Example: Line Fitting
Problem: Fit a Line Through 3 Data Points
Data: $(1, 1)$, $(2, 2)$, $(3, 4)$
Fitting the line $y = c_1 + c_2 x$ leads to the overdetermined system:
\[\begin{pmatrix}1 & 1 \\ 1 & 2 \\ 1 & 3\end{pmatrix}\begin{pmatrix}c_1 \\ c_2\end{pmatrix} = \begin{pmatrix}1 \\ 2 \\ 4\end{pmatrix}\] \[A = \begin{pmatrix}1&1\\1&2\\1&3\end{pmatrix}, \quad \vec{b} = \begin{pmatrix}1\\2\\4\end{pmatrix}\]Computing the normal equations:
\[A^TA = \begin{pmatrix}1&1&1\\1&2&3\end{pmatrix}\begin{pmatrix}1&1\\1&2\\1&3\end{pmatrix} = \begin{pmatrix}3&6\\6&14\end{pmatrix}\] \[A^T\vec{b} = \begin{pmatrix}1&1&1\\1&2&3\end{pmatrix}\begin{pmatrix}1\\2\\4\end{pmatrix} = \begin{pmatrix}7\\17\end{pmatrix}\]Solving the normal equations:
\[\begin{pmatrix}3&6\\6&14\end{pmatrix}\begin{pmatrix}c_1\\c_2\end{pmatrix} = \begin{pmatrix}7\\17\end{pmatrix}\]$\det(A^TA) = 3 \cdot 14 - 6 \cdot 6 = 42 - 36 = 6$
\[(A^TA)^{-1} = \frac{1}{6}\begin{pmatrix}14&-6\\-6&3\end{pmatrix}\] \[\hat{x} = \frac{1}{6}\begin{pmatrix}14&-6\\-6&3\end{pmatrix}\begin{pmatrix}7\\17\end{pmatrix} = \frac{1}{6}\begin{pmatrix}98-102\\-42+51\end{pmatrix} = \frac{1}{6}\begin{pmatrix}-4\\9\end{pmatrix} = \begin{pmatrix}-2/3\\3/2\end{pmatrix}\]Best-fit line: $y = -\dfrac{2}{3} + \dfrac{3}{2}x$
Geometric Meaning and the Residual
The Residual Is Orthogonal to the Column Space
The residual at the least squares solution $\hat{x}$:
\[\vec{r} = \vec{b} - A\hat{x}\]This residual is orthogonal to the column space $C(A)$:
\[A^T\vec{r} = A^T(\vec{b} - A\hat{x}) = A^T\vec{b} - A^TA\hat{x} = \vec{0}\]For the example above:
\[A\hat{x} = \begin{pmatrix}1&1\\1&2\\1&3\end{pmatrix}\begin{pmatrix}-2/3\\3/2\end{pmatrix} = \begin{pmatrix}5/6\\7/3\\19/6\end{pmatrix}\] \[\vec{r} = \begin{pmatrix}1\\2\\4\end{pmatrix} - \begin{pmatrix}5/6\\7/3\\19/6\end{pmatrix} = \begin{pmatrix}1/6\\-1/3\\5/6\end{pmatrix}\]Sum of squared residuals: $|\vec{r}|^2 = \frac{1}{36} + \frac{1}{9} + \frac{25}{36} = \frac{1+4+25}{36} = \frac{30}{36} = \frac{5}{6}$
Least Squares via QR Decomposition
Substituting the QR decomposition $A = QR$ into the normal equations simplifies things considerably:
\[A^TA\hat{x} = A^T\vec{b}\] \[(QR)^T(QR)\hat{x} = (QR)^T\vec{b}\] \[R^T Q^T Q R\hat{x} = R^TQ^T\vec{b}\] \[R^TR\hat{x} = R^TQ^T\vec{b}\] \[R\hat{x} = Q^T\vec{b}\]Since $R$ is upper triangular, this can be solved efficiently by back substitution. This approach is numerically more stable than computing $(A^TA)^{-1}$ directly.
Summary
| Concept | Formula / Description |
|---|---|
| Goal | Minimize $|A\vec{x}-\vec{b}|^2$ |
| Normal equations | $A^TA\hat{x} = A^T\vec{b}$ |
| Least squares solution | $\hat{x} = (A^TA)^{-1}A^T\vec{b}$ |
| Geometric meaning | $A\hat{x}$ is the projection of $\vec{b}$ onto $C(A)$ |
| Residual | $\vec{r} = \vec{b} - A\hat{x}$ |
| Residual property | $\vec{r} \perp C(A)$, i.e., $A^T\vec{r} = \vec{0}$ |
| Via QR decomposition | $R\hat{x} = Q^T\vec{b}$ (numerically stable) |
| Applications | Linear regression, data fitting, signal reconstruction |
In the next post, we introduce the Singular Value Decomposition (SVD), the most powerful matrix factorization in linear algebra – one that decomposes any matrix into three simple transformations.